
一、 概述:从“静态助手”到“终身学习者”
在大模型(LLM)领域,Agent 正在经历一场深刻的范式转移:从单纯的指令遵循者进化为能够进行长期规划和问题解决的终身智能(Lifelong Intelligence)系统。虽然现有的 Agent 在推理和工具使用上取得了长足进步,但其记忆管理与进化能力仍处于探索阶段。
Google DeepMind 提出的 Evo-Memory 是首个系统性评估 Agent 在流式任务(Streaming Tasks)中表现的基准和框架。它要求 Agent 不仅仅是检索事实,更要在部署期间通过不断的交互进行“测试时学习(Test-time Learning)”,实现记忆的动态累积、整合与更新。
论文地址:https://arxiv.org/pdf/2511.20857
二、 核心痛点:为什么 Agent “记住了话,却没学会事”?
目前的 Agent 记忆系统面临一个尴尬的现状:“记住了对话,却没学会经验”。
对话召回(Recall)vs. 经验复用(Experience Reuse): 现有的记忆模块多侧重于静态的对话历史保留,即对话召回,旨在记住“过去说了什么”。然而,真正的智能需要经验复用,即从过往的成功或失败轨迹中抽象出推理策略,以指导未来的决策。
重复犯错的问题: 面对连续的任务流时,缺乏经验复用能力的 Agent 往往会在类似的问题上重复犯错,无法通过历史交互沉淀出更优的策略。
自我进化的必要性:
效率瓶颈: 如果 Agent 无法进化,处理复杂任务的推理步骤将始终保持高位,无法通过经验积累实现路径优化。
适配成本: 在环境和任务不断变化的现实场景中,冻结权重(Frozen Weights)的模型必须具备在“测试时”实时适配的能力,而不仅仅是依赖预训练阶段获得的静态知识。
三、 以前的研究:TTL 与 TTA 的局限
在 Evo-Memory 之前,研究者们已经在尝试解决模型的动态适配问题,但仍存在局限:
测试时适配 (TTA): 早期研究主要侧重于处理分布偏移(Distribution Shift),且多针对视觉模型等非 Agent 场景。
测试时学习 (TTL): 近期 TTL 的研究开始引入反射(Reflection)和规划(Planning)机制,使 Agent 能够修正行为。然而,这些方法往往缺乏统一的记忆演进架构。
现有基准的局限: 例如 StreamBench 侧重于事实保留而非推理复用;Lifelong-Bench 虽然研究跨环境学习,但缺乏对记忆结构深度建模和更新的评估。这导致行业迫切需要一个统一的框架来衡量 Agent 如何在流式场景中进化策略。
四、 Evo-Memory 方案:构建“搜索-合成-进化”闭环
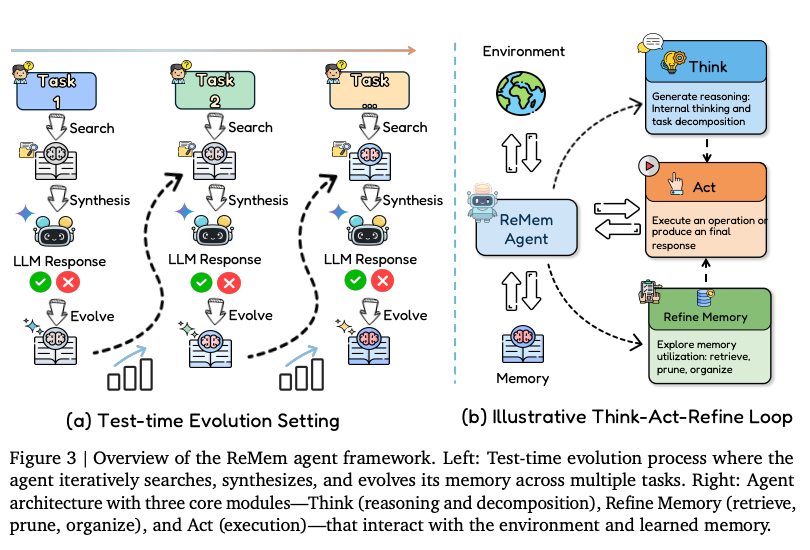
流式记忆模型
Evo-Memory将记忆 Agent 形式化为 (F,U,R,C) 四元组,定义统一的 Search-Synthesis-Evolve(搜索-合成-进化)循环。
记忆 Agent 的形式化定义:(F, U, R, C) 四元组
为了统一评估各种记忆架构(从简单的 RAG 到复杂的层次化存储),Evo-Memory 将增强型记忆智能体抽象为一个四元组:
F (Base LLM): 底座大语言模型,负责执行最终的推理和决策。
R (Retrieval Module): 检索模块,定义了搜索策略。它根据当前输入 xt 从记忆池 Mt 中寻找相关条目(如相似性搜索或索引查找)。
C (Contextual Construction): 上下文构建机制,负责合成逻辑。它将检索到的碎片化信息转化为 Agent 可理解的工作上下文(Working Context)。
U (Memory Update): 记忆更新流水线,负责进化过程。它决定了任务完成后,如何将新经验(含反馈)整合进原始记忆池中。
Search-Synthesis-Evolve(搜索-合成-进化)闭环逻辑
这个循环模拟了人类“遇到问题-调动经验-总结提升”的认知过程,Agent 沿着输入序列 {x1,x2,…,xT} 持续演进:
Search(搜索):捕捉相关经验
在时刻 t,Agent 接收到新任务 xt,通过检索模块 R 识别出最相关的历史记忆条目 Rt=R(Mt,xt)。这一步保证了 Agent 能在数千个历史片段中快速定位“曾经解决过类似问题”的方法。
Synthesis(合成):重构工作上下文
Agent 不再是原始数据的堆砌者,而是利用合成机制 C 将检索到的信息解读并重构为简洁的、针对当前任务优化的 In-context 提示词。这可能包括形成结构化提示、筛选核心条目或生成总结摘要。
Evolve(进化):从结果中自我迭代
在产出回答 y^t 后,系统会根据任务的成功与否(反馈 ft)构建一个新的经验条目 mt。
更新模块 U 将其整合进记忆池:Mt+1=U(Mt,mt)。这种更新不仅是“追加”,也可能涉及压缩、摘要或根据容量限制进行替换。
流式记忆的“终身学习”特征
这种流式模型的设计使得 Agent 展现出与传统模型截然不同的特性:
测试时自适应(Test-time Adaptation): 即使模型权重被冻结,Agent 也能通过记忆池的演进,在部署期间实时调整其解决问题的策略。
经验复用而非事实召回: 传统的“对话召回”只记住过去说了什么,而 Evo-Memory 强调的是经验复用——从过去的成败轨迹中抽象出推理模式(如特定的数学公式或操作顺序),并应用到后续任务中。
累积优势: 随着处理的任务增多,记忆状态 Mt 不断精炼,使得 Agent 在处理极长序列任务时能够保持稳定并表现出比“冷启动”阶段更快的收敛速度。
ExpRAG (简单经验检索)
核心定义与设计理念
ExpRAG 的核心目标是让智能体不仅仅是简单地回忆对话历史,而是能够抽象并复用过去的推理策略来解决未来的任务。与传统的仅关注事实检索的 RAG 不同,ExpRAG 专注于任务级(Task-level)的经验沉淀。
工作机制
ExpRAG 将记忆视为一个动态演化的库,其运行遵循以下流程:
经验编码(Encoding):每个记忆条目都会被编码为结构化的经验文本,通常包含任务输入、模型生成的预测以及最终的反馈信号(如任务是否成功)。
检索(Search):当遇到新任务时,系统会计算当前输入与记忆库中条目的相似度,并检索出 Top-k 个最相关的历史经验。
聚合与合成(Synthesis):ExpRAG 遵循上下文学习(In-context Learning)原则,将这些检索到的经验示例直接作为背景信息嵌入到提示词中,引导 LLM 生成响应。
演化(Evolve):在完成当前任务后,ExpRAG 会将此次的新经验(包含输入、输出和反馈)追加到记忆库中,以便在后续任务中被检索。
主要优势与特点
简单且高效:尽管其设计逻辑相对直接,但实验表明 ExpRAG 是一个极其有效的基线。在单轮推理和问答基准测试(如 ToolBench)中,它的表现甚至优于一些更为复杂的记忆设计。
提高任务效率:通过复用类似任务的成功策略,ExpRAG 能显著减少智能体完成任务所需的步骤。例如,在 AlfWorld 等环境中,它能帮助模型以更简洁的推理路径达成目标。
鲁棒性强:在面对任务难度变化(如从简单任务过渡到困难任务)的分布偏移时,ExpRAG 比不具备持续学习能力的系统表现得更加稳定。
局限性
虽然 ExpRAG 提升了经验复用能力,但它属于一次性(One-shot)的经验利用方式。相比于更先进的 ReMem 框架,ExpRAG 缺乏迭代推理和在推理过程中主动重组记忆的能力。它本质上是将检索到的经验作为静态示例使用,而无法在解决问题时对记忆进行深度的思考或修剪。
总的来说,ExpRAG 在 Evo-Memory 研究中证明了:显式的任务级经验复用是提升轻量化 LLM 在现实流式任务中适应能力的一个极具前景且尚未被充分探索的方向。
ReMem (高级智能体循环)
传统的智能体(如 ReAct 模式)通常只在“推理(Think)”和“行动(Act)”两个维度运行。ReMem 引入了第三个关键维度——记忆推理(Memory Reasoning)。 这使得智能体不再是被动地将记忆作为静态上下文检索,而是能够在解决问题的过程中,主动评估、重组和演化自己的记忆
工作机制:Think-Act-Refine 循环
在每一个任务步骤中,ReMem 智能体会从以下三种操作中进行选择:
思考 (Think):生成内部推理链,帮助分解任务并指导后续行动。
行动 (Act):在环境中执行操作(如调用工具)或向用户输出最终响应。一旦选择此操作,该步骤即宣告结束。
精炼 (Refine):对记忆进行元推理(Meta-reasoning)。这包括利用有用经验、修剪干扰噪声以及重新组织记忆库,以更好地支持未来的推理和行动。
在该流程下,智能体可以在正式执行“行动”之前,进行多轮的“思考”和“精炼”。
主要优势与特点
显著提升任务效率:实验表明,ReMem 能大幅减少完成任务所需的步骤。例如,在 AlfWorld 环境中,它将平均操作步骤从 22.6 步缩短到了 11.5 步。
极强的鲁棒性与适应性:在面对任务难度剧烈波动(如从简单任务突然切换到极难任务)时,ReMem 比基础模型和简单的检索方法表现得更稳定。
错误学习能力:ReMem 能够处理包含失败案例的记忆。通过“精炼”机制,它能主动识别并剔除无用的失败经验,或从中提取教训,从而在含有噪声的经验库中保持高性能。
赋能轻量化模型:ReMem 对小型 LLM(如 Gemini Flash 或 Claude Haiku)的提升尤为显著,为增强轻量化模型在复杂任务中的表现提供了一条切实可行的路径。
ReMem vs ExpRAG
相比于之前提到的 ExpRAG(一种简单的一次性经验检索与聚合方法),ReMem 更加动态和深入。ExpRAG 只是将过去的经验作为静态示例放入提示词,而 ReMem 则赋予了智能体“反思自己知道什么”以及“如何优化现有知识”的能力。
总的来说,ReMem 通过将记忆管理融入智能体的实时决策循环,建立了一种自适应、自改进的智能体新标准。
Evo-Memory Benchmark 方案:从静态评估到流式演进
为了填补现有基准在“经验复用”评估上的空白,Evo-Memory 设计了一套全新的评估范式:
数据流式重构(Streaming Restructuring): Evo-Memory 将原本静态的、独立的测试题目重构为连续的任务流序列。这种设计的核心逻辑是:前序任务的成功经验或失败轨迹,应成为解决后续类似任务的关键线索。通过这种方式,它能够显式地探测模型在部署期间累积、适配和精炼知识的能力。
全场景任务覆盖: 该基准涵盖了从单轮推理到多轮交互的多元化任务,确保了评估的全面性:
单轮推理与 QA: 包含 MMLU-Pro(多学科推理)、GPQA-Diamond(专家级科学问题)、AIME 24/25(奥数级数学竞赛)以及 ToolBench(API 调用与工具使用)。
多轮交互与具体化环境: 采用了 AgentBoard 套件,包括 AlfWorld(家庭指令遵循)、BabyAI(导航与逻辑推理)、ScienceWorld(科学实验)、PDDL(符号规划)等。
多维度的评价体系: 不同于传统仅看准确率的指标,Evo-Memory 提出了四个维度的深度评估:
回答准确率(Accuracy): 评估模型整合过往经验进行推理的最终效果。
成功率与进度率(Success/Progress Rate): 针对多轮交互任务,衡量 Agent 完成复杂目标的效能。
步骤效率(Step Efficiency): 这是一个关键指标,用于观察记忆是否让 Agent 的推理更简洁。例如,进化后的 Agent 是否能用更少的步数达成目标。
序列鲁棒性(Sequence Robustness): 测试 Agent 在不同任务顺序(如从易到难或从难到易)下的稳定性,反映其经验复用的稳健程度。
五、 效果分析:性能与效率的双重飞跃
性能(Performance)
在数学、科学推理和 API 调用等任务中表现出极强的跨数据集泛化性。
鲁棒性:在任务难度剧烈波动(Easy ↔ Hard)时,依然能通过累积经验保持稳定。
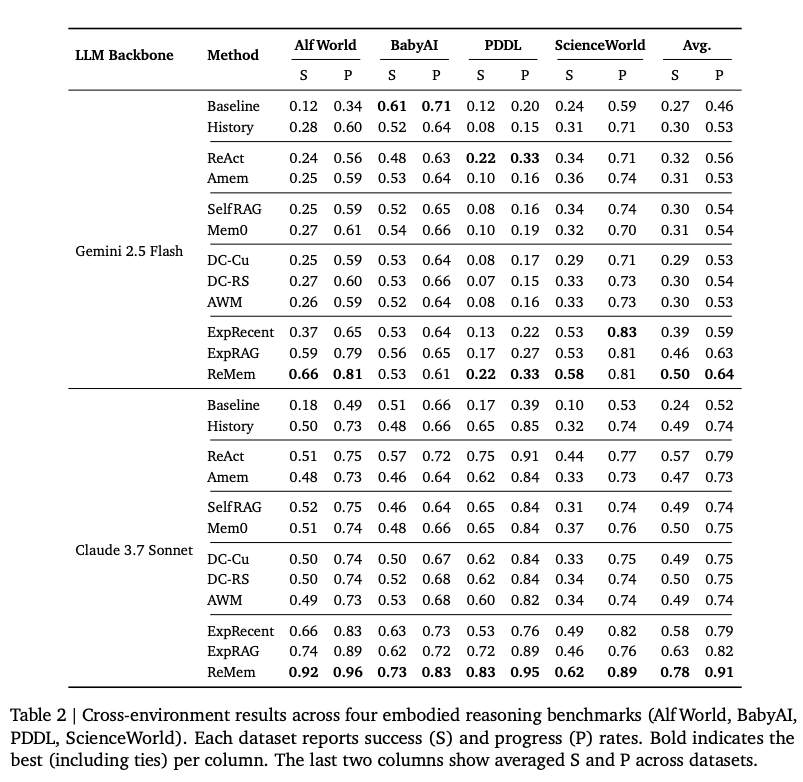
效率(Efficiency)
步骤缩减:ReMem 能显著减少完成任务所需的步数(例如在 AlfWorld 中减少约 50%)
快速适配:对比曲线显示 ReMem 在处理少量任务后即可迅速超越传统 History 模式。
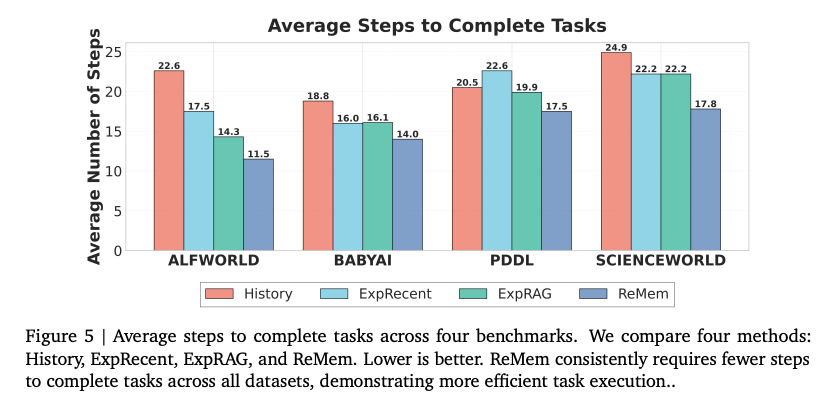
六、 总结与展望:冻结权重下的“进化之光”
“后天学习”的崛起
大语言模型的冻结权重如同人类出生时自带的大脑结构与基因序列,虽然在部署阶段无法被直接改写,但这并不意味着智能的止步。
从静态回忆到动态进化:传统的RAG模型仅能做到“事实检索”,类似于翻阅参考书;而通过Evo-Memory框架下的ExpRAG和ReMem机制,智能体实现了从“记住说了什么”到“学会了如何做”的跨越。这正如人类通过后天教育和训练,在不改变基因的前提下,通过经验的自组织与自精炼(Refine),获得了超越本能的任务适配性。
模拟“神经可塑性”的记忆架构:Titans架构通过一种长效神经记忆模块(LMM),在测试时动态学习并存储抽象经验。这种机制模拟了人类大脑在处理惊奇(Surprise)事件时更易形成长期记忆的特质,使得模型能在不调整权重的“数字化基因”下,依然表现出强大的持续改进能力。实验证明,这种“后天训练”能显著提升智能体在复杂环境(如AlfWorld)中的任务效率,将操作步骤缩短近一半。
“终身智能”的进化路径
类比人类在成长过程中面临的挑战,未来冻结权重模型下的进化将集中在以下维度:
噪声经验的过滤与甄别(反馈质量的影响): 人类在学习中会遇到错误的指导,智能体亦然。目前的实验显示,未经筛选的失败经验(Failed experiences)会干扰模型的判断。未来的研究需探索如何像人类反思错误一样,让模型具备错误感知能力,从噪声或不完美反馈中提取“教训”而非盲目记忆。
跨越时空的记忆韧性(长程稳定性): 在极长的时间跨度下,人类面临记忆模糊,而智能体则面临“记忆坍塌”或溢出的风险。如何在不改变大脑基础(权重)的情况下,通过更精妙的遗忘机制(Forgetting Mechanism)和权重衰减,在数百万甚至无限长度的序列中保持核心知识的稳定,是实现“终身智能”的关键。
总的来说,冻结的权重并非智能的终点,而是进化的起点。通过在上下文空间中构建一套类似人类经验积累的自进化记忆系统,AI正逐步在不可调的基因框架内,书写出属于自己的动态进化史。